
Begin februari 2026 werkte Google de documentatie van Googlebot bij. De opvallendste wijziging: Googlebot crawlt maximaal 2MB HTML per pagina. Dat klinkt als een forse verlaging ten opzichte van de eerder gedocumenteerde 15MB. Maar het verhaal is genuanceerder dan de koppen suggereren.
Wat is er precies veranderd?
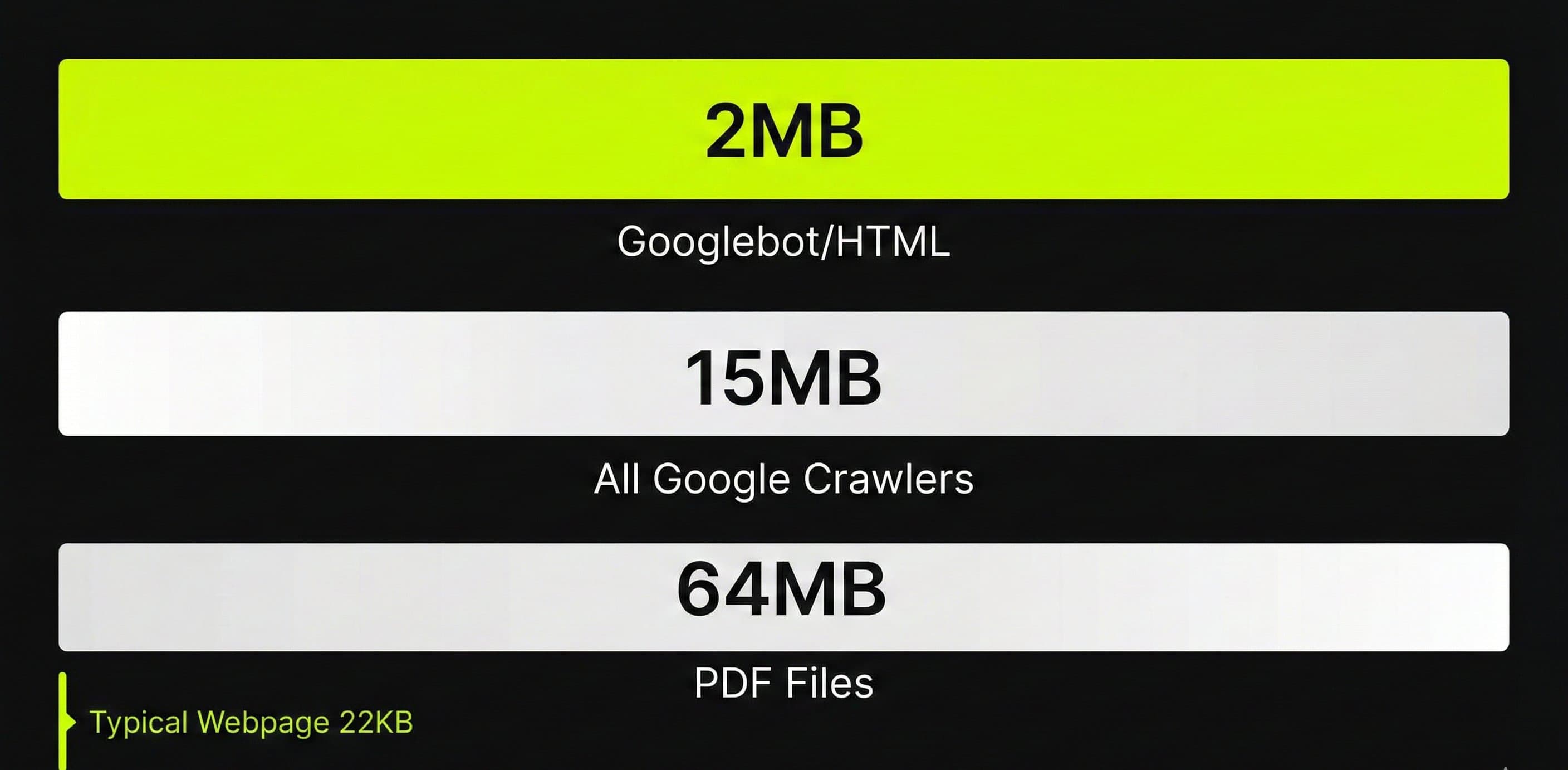
Op 4 februari 2026 verplaatste Google informatie over crawl-limieten van de Googlebot-documentatie naar de bredere crawler-documentatie. Tegelijk voegden ze specifiekere limieten toe voor Googlebot zelf. Het resultaat: drie verschillende limieten die elk voor een ander onderdeel gelden.
De drie Google crawl-limieten:
- 2MB voor HTML en ondersteunde bestandstypes (Googlebot specifiek, voor Google Search)
- 64MB voor PDF-bestanden (Googlebot specifiek)
- 15MB standaard voor alle Google crawlers en fetchers (inclusief AdsBot, Feedfetcher, etc.)
Google zelf benadrukt dat het gedrag niet is veranderd. John Mueller schreef op Bluesky: “None of these recently changed, we just wanted to document them in more detail.” De 2MB limiet bestond waarschijnlijk al jaren, maar was nooit eerder apart gedocumenteerd.
Het onderscheid is belangrijk: Googlebot (de crawler voor Google Search) heeft een lagere limiet dan Google's andere crawlers. De 15MB die sinds Gary Illyes' blogpost in 2022 gedocumenteerd stond, gold voor de gehele crawler-infrastructuur. Nu is duidelijk dat Googlebot zelf strenger is.
Wat gebeurt er als je pagina groter is dan 2MB?
Google's documentatie is hier expliciet over: “Once the cutoff limit is reached, Googlebot stops the fetch and only sends the already downloaded part of the file for indexing consideration.”
Concreet betekent dit:
- Googlebot stopt met downloaden zodra 2MB bereikt is
- Alleen het reeds gedownloade deel gaat naar indexering
- Alles na de 2MB-grens wordt genegeerd: niet gecrawld, niet geïndexeerd
- De limiet geldt voor ongecomprimeerde data (niet de transfer size)
Dat laatste punt is cruciaal. Je server gebruikt waarschijnlijk gzip-compressie, waardoor de transfer kleiner is. Maar Googlebot meet de volledige ongecomprimeerde grootte. Een pagina die 800KB over de lijn gaat, is na decompressie al voorbij de 2MB.
Wat kun je verliezen bij overschrijding?
De gevolgen zijn afhankelijk van waar je content staat in de HTML. Als structured data, interne links of belangrijke content onderaan de pagina staan en de HTML daarvoor al groot is, worden die simpelweg afgeknipt. Denk aan:
- Structured data (JSON-LD) die onderaan de pagina staat
- Interne links in de footer die niet meer gecrawld worden
- Productinformatie die pas later in de HTML verschijnt
- Rich results die verdwijnen omdat de schema markup gemist wordt
Moet je je zorgen maken?
Kort antwoord: waarschijnlijk niet. De mediane HTML-pagina is slechts 22KB (bron: Web Almanac 2025). Het 90e percentiel zit op circa 155KB. Om de 2MB-grens te bereiken, moet een pagina ongeveer 90 keer groter zijn dan gemiddeld.
John Mueller plaatste het in perspectief: “It's extremely rare that sites run into issues in this regard. 2MB of HTML is quite a bit. 90% of pages have less than 151kb HTML.”
Om het concreet te maken: 2MB HTML staat gelijk aan circa 2 miljoen tekens. Dat is een boek van 400 pagina's op een enkele webpagina. De gemiddelde bedrijfssite, blog of dienstenpagina komt daar niet in de buurt.
Vuistregel voor HTML-grootte:
- Onder 500KB: geen enkel probleem, geldt voor 99% van alle websites
- 500KB tot 1MB: veilig, maar wees bewust van de grootte
- 1MB tot 2MB: optimaliseren is verstandig, zeker als je groeit
- Boven 2MB: actie vereist, Google kapt je content af
Welke sites lopen wél risico?
Hoewel het voor de meeste sites irrelevant is, zijn er specifieke scenario's waar de 2MB-grens een reëel probleem kan zijn.
E-commerce met inline productdata
Webshops die duizenden productvariaties als inline JSON-data in de HTML embedden voor client-side rendering. Een categoriepagina met 500 producten en al hun attributen in een JSON-object kan moeiteloos 2MB overschrijden.
Single Page Applications met grote JS-bundels
SPA's die hun volledige applicatiecode als inline JavaScript in de HTML plaatsen. Moderne JS-bundels zijn vaak 500KB tot 1,5MB gecomprimeerd. Ongecomprimeerd kunnen ze meerdere megabytes bereiken. Elke resource (CSS, JS) die apart wordt geladen heeft dezelfde 2MB limiet.
Pagina's met volledige datasets
Vergelijkingspagina's, prijslijsten of interactieve tools die hun complete dataset in de initiële HTML laden. Als je een financieel vergelijkingsplatform bouwt met duizenden tarieven inline, kan dat optellen.
Dave Smart, een gerespecteerde technical SEO, zette het in perspectief: “At the risk of overselling how much of a real world issue this is: it really isn't for 99.99% of sites I'd imagine.”
Hoe check je de HTML-grootte van je pagina's?
Wil je zeker weten dat je site binnen de limiet zit? Er zijn meerdere manieren om de ongecomprimeerde HTML-grootte te meten.
Chrome DevTools
Open je pagina in Chrome, druk F12, ga naar het Network-tabblad en herlaad de pagina. Zoek het HTML-document (meestal het eerste item) en bekijk de kolom “Size”. Let op dat je de ongecomprimeerde grootte bekijkt, niet de transfer size. Klik op het document en check de Response headers voor de volledige grootte.
Screaming Frog
Crawl je site met Screaming Frog SEO Spider. De kolom “Size” toont de ongecomprimeerde grootte per URL. Filter op pagina's groter dan 1MB om potentiële problemen snel te spotten.
Tame the Bots Fetch & Render
Dave Smart bouwde een Fetch & Render tool die specifiek de 2MB truncatie simuleert. Je ziet precies wat Googlebot wel en niet zou zien van je pagina. John Mueller endorsede deze tool op Bluesky op 6 februari 2026.
View Source methode
De snelste check: rechtermuisklik op je pagina, “Paginabron weergeven”, selecteer alles (Ctrl+A), kopieer naar een teksteditor en sla het op als bestand. De bestandsgrootte is je ongecomprimeerde HTML-grootte.
Praktische tips om binnen de 2MB te blijven
Zelfs als je ver onder de limiet zit, is lean HTML goed voor je crawl-efficiëntie en technische SEO in het algemeen.
- Gebruik externe stylesheets en scripts.
- Inline CSS en JavaScript tellen mee voor de HTML-grootte. Externe bestanden worden apart gecrawld, elk met hun eigen 2MB limiet.
- Vermijd inline JSON-datasets.
- Laad productdata, prijslijsten of andere grote datasets via API-calls in plaats van ze in de initiële HTML te embedden.
- Zet structured data bovenaan.
- Als je JSON-LD schema markup gebruikt, plaats deze in de head of vroeg in de body. Bij truncatie is het dan al gecrawld.
- Zet belangrijke content vroeg in de HTML.
- John Mueller adviseert: “Make sure to have important stuff in a reasonable place, and not only on the bottom.”
- Pagineer lange lijsten.
- Een categoriepagina met 500 producten? Splits die op in pagina's van 50. Beter voor gebruikers, beter voor crawlers.
- Verwijder overbodige HTML.
- Inline styles die door een CMS worden gegenereerd, dubbele wrapper-divs, ongebruikte code. Elk onnodig karakter telt mee.
De relatie met crawl budget
De bestandslimiet en crawl budget zijn verwante maar verschillende concepten. Crawl budget bepaalt hoeveel URL's Googlebot kan en wil crawlen van je site. De bestandslimiet bepaalt hoeveel van een individuele pagina Google leest.
De relatie is indirect: grotere bestanden kosten meer bandbreedte en tijd per crawl. Als elke pagina op je site 1,5MB HTML is, kan Googlebot minder pagina's crawlen in dezelfde tijdspanne dan wanneer ze elk 50KB zijn. Google zegt zelf: “If Google can load and render your pages faster, they might be able to read more content from your site.”
Voor sites met minder dan 10.000 pagina's is crawl budget zelden een issue. Voor grote e-commerce sites met honderdduizenden URL's wordt die efficiëntie wél relevant.
Samengevat: wat moet je onthouden?
De 2MB limiet is geen nieuwe beperking. Google heeft bestaand gedrag verduidelijkt in de documentatie. De 15MB geldt nog steeds voor Google's crawlers in het algemeen. De 2MB is specifiek voor Googlebot bij het crawlen voor Google Search.
Voor de overgrote meerderheid van websites verandert er niets. Je gemiddelde pagina is 22KB. Zelfs een uitgebreide productpagina of een lang blogartikel komt zelden boven de 200KB. De 2MB-grens is pas relevant als je werkt met grote inline datasets, zware SPA's of pagina's die volledige productcatalogi in de HTML embedden.
Wat je wél kunt doen: houd je HTML lean, zet belangrijke content en structured data vroeg in je broncode, en gebruik externe stylesheets en scripts. Dat is geen paniekactie voor de 2MB-limiet, dat is gewoon goede technische SEO.
Wil je weten hoe jouw site technisch scoort?
Van crawl-limieten tot Core Web Vitals: een technische check laat zien waar je kansen laat liggen. Bel: 06 282 064 10. Of plan een gesprek.
PLAN EEN GESPREK

